
So, I want to beg those involved in algorithmic design, particularly those claiming their work is 'generative', to explore
- Chomsky's linguistics, basically transformational generative grammar
- linguistic 'pragmatics', which in claims to be taking over from Chomsky
- statistical machine translation, which really has taken over from Chomsky, for now
and to see where this might lead, and help with, computational design. Here's some short notes.
Chomksy's linguistics was explicitly computational from way back in 1955. The work he wrote then, to underpin his PhD, was called The Logical Structure of Linguistic Theory and it led him to develop the concept of a grammar hierarchy, now known as the Chomsky Hiearachy.
This hierarchy demonstrates how automata - meaning 'theoretical computers' - of differing levels of technical power were limited and enabled to differing levels of grammatical - that is, 'language-interpreting' - computational capacity.
This contribution is so foundational to theory of computation that it is routinely included in reviews of the field ... without being referenced to Chomsky!
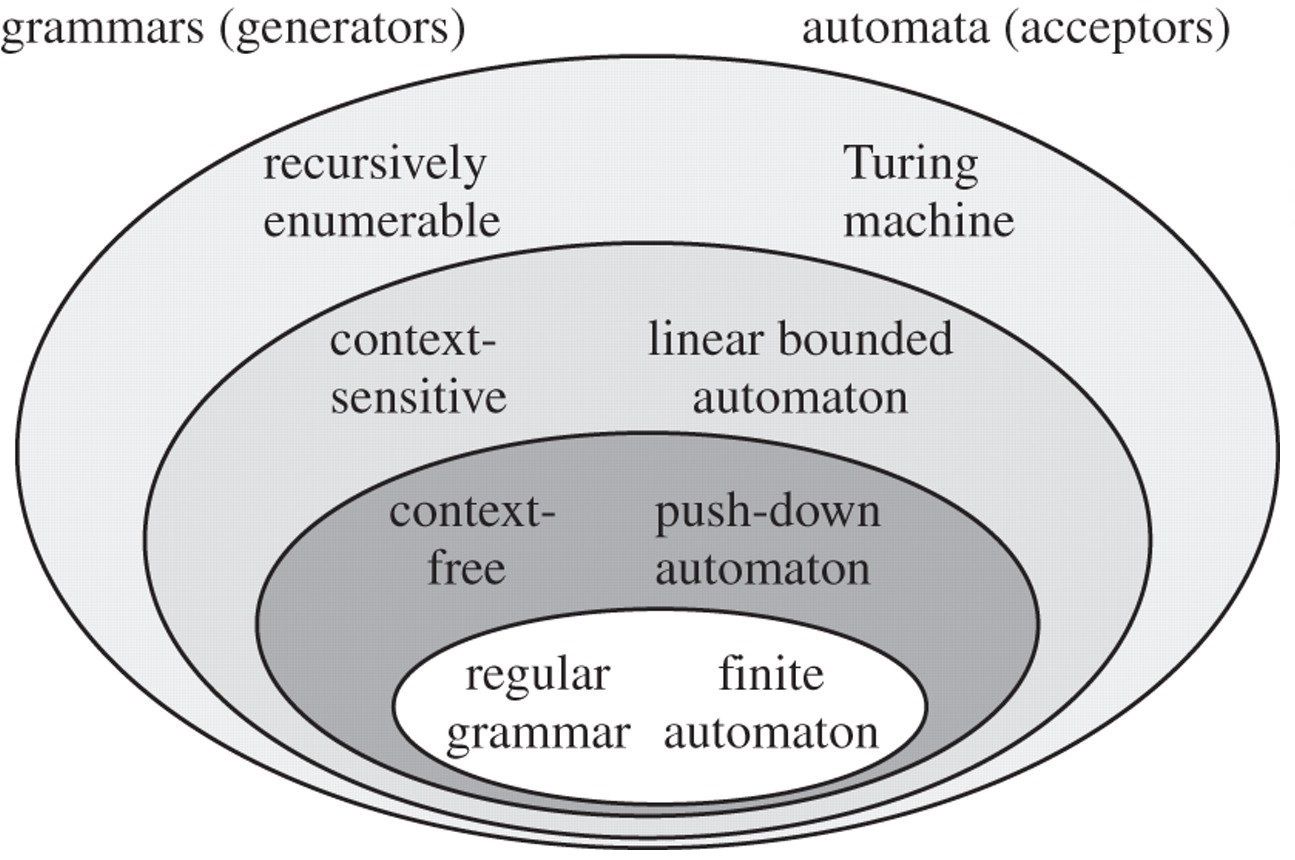
These insights and analysis, based on his biosocial questions around how humans can form so many meaningful utterances at a young age with so little exposure to language, gave rise to his whole paradigm of linguistics research, originally called transformational generative grammar: a proto-computational approach in which limited inputs (ie a lexicon of words) are transformed by syntax rules to generate intelligible language outputs.
And this generative approach to language is so powerful that it caused a so-called generative turn in linguistics and related fields. Central to the generative model is a set of configuration rules for syntactic units: which words may sit together which which other words to make correct sentences, and how sentences must be 'rewritten' in the mind before utterance, to make them work according to the rules.
While generativism is weakening in linguistics, and we'll see why, it should be stronger—and will likely become strong again. That's why I'm writing this note!
It should be stronger because the core premise - quasi-infinite outputs from finite inputs using finite rules - is a signature feature in so much of science, and not just modern computational code. Genetics, physics, chemistry, and much more, use the elements >> rules >> transformations approach that Chomsky pioneered back in the 1950s.
Anyone now familiar with the procedural generation of design forms using, for example, the so-called Wave Function Collapse (WFC) algorithm will recognise this formal generativism: limited inputs, limited rules, quasi-infinite outputs.
For myself, I am shocked that no-one is making the obvious connections between these premises. This is because taking procedural design under the analytical wing of quantum physics (hence the name Wave Function Collapse), is far less likely to guide progress than taking it under the wing of linguistics!
CHOMSKYAN DECLINE AND LINGUISTIC PRAGMATICS
Chomsky's generative paradigm in linguistics has two devastating flaws: it's doesn't work that well for anything, and it doesn't apply at all to everything. Meaning that even in English, for which it is built, it is very hard to use it to generate always-perfect sentences, and this is very odd since it that is what it is built for.
So, the history of generative linguistics has been one of incremental, and occasionally systemic, reformulations of the generative model.
The more complete failure of the generative model we'll look at a bit later, but the initial failure is something almost parallel to the overall syntactic approach, and it is the limits of the generative model to capture actual meaning in a lot of real world contexts.
For example, the same grammatically-correct sentence—"that's a great attempt!"—has very different meaning depending on whether it is presented as a sincere ... or ironic ... comment on a particular action.
Chomskyan grammar has no machinery at all to deal with this contextual marker of meaning, not even tone of voice, since none of that has any bearing on the rule-based syntactic correctness of the sentence as a string of words.
Similarly, if you are asked, "which cake would you like?" at a bakery counter, and you reply, "I want that one"—without pointing to any—you won't be able to get the cake you want - even though you have generated a perfectly meaningful sentence in response to the question.
In this case, the phenomenon of deixis—pointing—must be contextually supplied outside of the sentence syntax to complete the meaning of the deictic (ie pointing) pronoun 'that'.

These are examples of what is now called linguistic pragmatics, and this are probably the main contemporary vector of attack inside linguistics on the Chomskyan paradigm: that the bottom-up, or grammar-endogenous, approach of generative linguistics doesn't actually reach out towards many, or even most?, of the human circumstances in which language is supposed to be the main co-ordinating tool.
The most enflamed aspect of how pragmatics challenges Chomsky is in talking up cultural context and how widely it diverges, and thus appears to defy the universality that marks Chomsky's approach to grammar.
For example, while actual pointing is required in English to complement the deictic pronouns, it is considered offensive, apparently, in some cultures to point with the finger, or the hand at all. So, yes, some kind of gestural implication may be needed in context to boost the word-based syntax, which is the first level of pragmatics insight; but this gesture is not the same across cultures, and thus broader contexts, which is the second level of pragmatics insight.
How this pragmatics turn, which is still immature having only asserted itself from the 1970s onwards, will drive linguistics forward is not fully clear, and it's even less clear how it might contribute by analogy to spatial design.
But I'll hazard some examples - which since I think I am the only person trying this and it is very low on my list of priorities (and competencies!) - will be pretty limited!
One way of thinking of the mismatch of (endogenous) procedural generation vs (exogenous) contextual issues in spatial design is to think of things that the spatial form must cater for and influence, but cannot control.
This is parallel by analogy to the deictic ('this' or 'that') pronouns that have to be used for your finger-pointing to make much sense: are spatial forms complete or meaningful without a behavioral complement that must be supplied?
So, to take for example some procedurally generated examples from Oskar Stålberg's #Townscaper digital-spatial creativity toy, we could focus say on the water-based nature of the towns created, or the washing lines that appear strung between walls on occasion.
Obviously, this is a work of imagination, but if we were to apply this kind of thing to the real world, we would be making the assumption that boats were available, or the town's users didn't use dyers for their clothes.

Without those exogenous facts being in place, the endogenous facts of steps down to the water, and clothing lines with drying clothes, would make little sense.
This raises the profound question of primacy: what drives what? Do exogenous factors such as behaviour, geography, technology, preferences, drive spatial forms? Or do available spatial forms drive how we end up framing - that is, limiting and imagining - our real-life contexts?
This question is essential to the value of computational design: how or why would you generate optimization and automation tools for designs that no-one can or will use? It would be like designing 'better' cars for a world without drivers. Of, if you like: designing offices for people that aren't working in offices any more.
In language, you might translate (haha) that question like this: do limits on the power of words and language drive how we manage human situations beyond language? Or do situations drive how we develop our language tools?
CHOMSKYAN COLLAPSE AND STATISTICAL TRANSLATION
The biggest attack on generative linguistics has come from ... ignoring it almost entirely: this is the contribution of Google's leadership in machine translation.
Up until as recently as 2007 the machine translation tools were basically trying implement Chomsky's work: run the rules, generate the sentences.
But in that year, a different approach, statistical matching of large blocks (or corpuses) of translated texts, took over with the actual flick of a switch.
Google had amassed so much searchable text data in so many languages, so much statistical matching firepower, and come up against so much failing in the rule-based approach to translate, in which there were just so many "exceptions to the exceptions" to the rules that the … 'rules' weren't worth following any more.

And here we are today: with magical translation tools that guess how a translation would go, by matching parts of the input phrase to blend of outputs generated by vast amounts of similar, previous, actual human translations. Modern text generation tools follow very much the same approach: statistical matching of how previously written meaningful phrases follow on from each other to create whole texts, rather than rule-based generation of new utterances.
This is, indeed, the collapse of the Chomskyan generative paradigm based on rules, and the rise of a new generative paradigm based on pattern-matching statistics.
The same is not really happening yet in computational design, but not for any ideological or truly technical reason. It's definitely possible that machines could match up - 'translate' - design problem to a mass of previously solved problems.
It's just a set of practical facts that block a large-scale statistical approach to design automation, akin to Google's takedown of language translation:
- the history of spatial designs are mostly not in computatable form, they are drawings
- digital drawings are not in shared, standard formats
- the images inside digital drawings are not notated in ways that can be parsed accurately by a computer (for example, in most CAD drawings, the doors are recognisze as visual symbols, but are not digitally encoded as doors).
- and, in any case, most drawings are private and not available for research!
REFLECTIONS FOR THE GENERATIVE DESIGN AGE
Setting the scene like this for generative design, by explaining how Chomskyan syntax is proto-computational, and contrasting it with pragmatics and statistical translation, has I think some relevance to computational design synthesis in its various forms.
In the first place, it's important to distinguish between algorithmic design and generative design. Most computational design is currently just algorithmic: it 'generates' outputs with algorithms, but it doesn't do so with a limited set of primitive elements, or a finite set of rules. And as such, not only is it hard for different approaches to be reconciled with each other for cumulative learning, it's not even clear what the broader implications of any one design are to the creator. It's just automation.
One of the profound contributions Chomsky made to linguistics, and computation, theory was to demonstrate with his hierarchy that certain outputs are simply not possible from certain inputs or combination rules or other procedural features.
Now, treating spatial design even abstractly in the same way as language has the sad problem that there is, even after thousands of years of doing it, no truly stable way to define even the finite elements that combine to finished forms, let alone the combination rules. Just how primitive might the elements be? There are many candidates: lines, shapes, groups, objects (like doors), composites (like rooms), programs (types of spaces), etc.
But what computational design can and should learn from linguistic generativism is at least the discipline of boundedness of different types of automations: you can know where your model is limited, no matter how much power or how many iterations you throw at it.
In addition to this root learning from the earliest days of generativism, computational design can also learn upfront the message of the linguistic pragmatism practitioners: that is that, outside of both any live context, and separately outside of a cultural specific context, it's not clear how suitable or viable generated solutions are.
Taking the fully exogenous approach, of statistics, to guide design is, as we have noted, currently a bit impractical. But even as it gets solved, there are warnings.
If you take the best cases of statistical language generation, whether Google Translate or GPT-3, in both cases, the problems are very specific and pernicious:
- if the input is bad, the output is bad.
- unless you know what you are already looking for, indeed unless there are already good examples of what you are looking for in large quantities out there, then you will not be able (because the system will not be able) to recognise good new designs.
- if you need to make fine grain corrections to any specific model, the system not only cannot help you, it works implicitly against you since, once you have made a change, you don't know the relative merits of the design. The statistical comparison of one design that a human has made or adapted to all previous designs, is a different technical challenge to synthesising a design from all previous designs.
And there's a final problem:
- you really don't know how to improve the system without reviewing quasi-infinite examples and algorithms.
In statistical translation, it's easier for humans to rank the translation because the quality of the output is, within reason, subject to binary limits. It's a good or bad translation of the original.
But people don't speak the language of hyperstatistics. And hyperstatistical computers can't tell people what they mean by this or that feature - because this or that not only doesn't mean anything, it doesn't even really exist as far as the computer is concerned.
A sentence, or a built form, is just a composite ranked on a statistical list: its elements have no measurable, finite meaning or value on their own.
That is: in new statistical generation, the computer cannot itself critique an individual item it has generated to the whole corpus, since it has no grounds to do so: it generated it on the basis of its understanding of that corpus.
And individuals can't do that comparison, nor can they feed back their views into the system, since they would be statistically irrelevant.
WFC AND NEXT STEPS IN PROCEDURAL MODELLING
We can review these reflections in the context of a popular technique for design generation at the moment, WFC. WFC has an interesting property in that it broadly links the Chomskyan-generative (ie limited-rule-and-element-based) and statistical-generative paradigms.
While the elements of the design are chosen from a limited set, with a limited set of rules to combine them, the ultimate choice of which tile comes next, as complexity of a procedural generation continues, is based on statistical analysis of the property of that tile.
But even if WFC, when set to automatic—composite forms generated by machines—can help give us a balance between true generative design, and statistical modelling - which is already progress in terms of learning from the history of generativism - there are two overwhelming problems if might want to apply this to real world contexts.
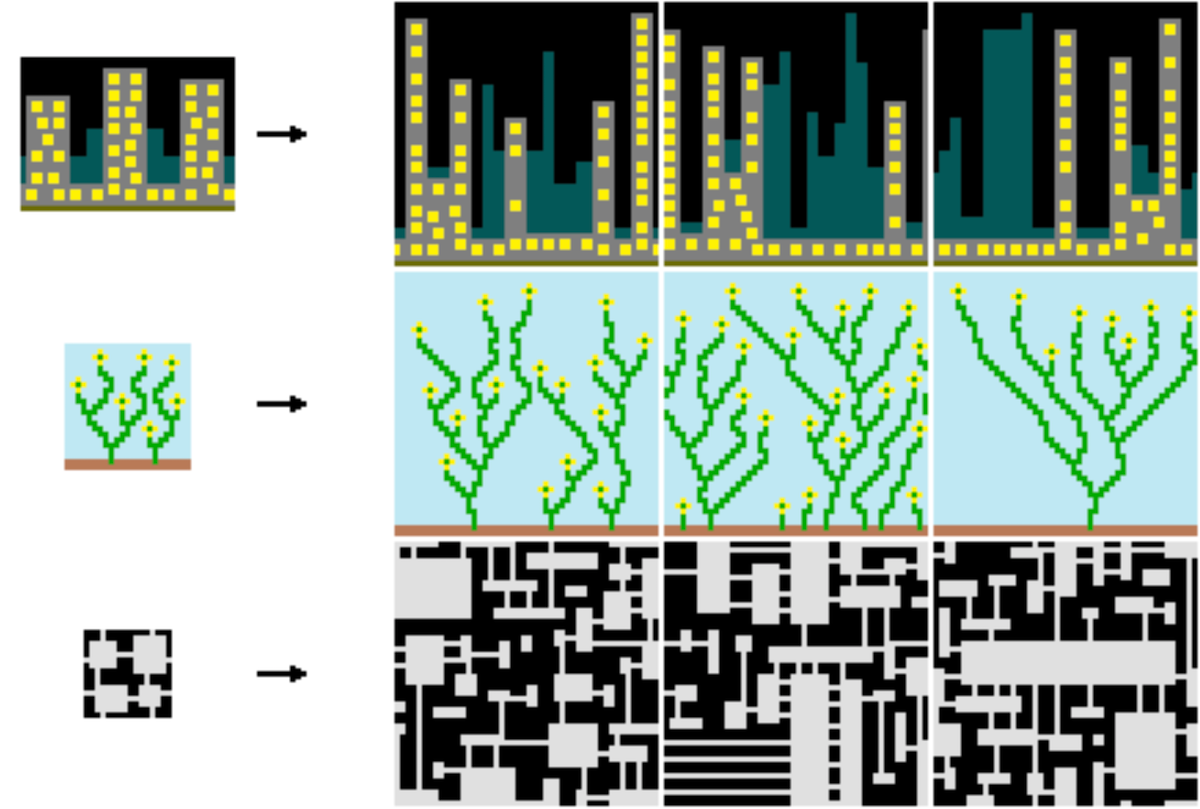
Firstly, even if we had in the spatial and built domains a stable set of primitives to work from, and construct theories on, as we do somewhat in language and other generative fields (natural sciences) - and we don't - the higher order complexity is truly vast.
Specifically, projects like Space Syntax and Topologic are explicitly building up rule-(or at least pattern-) based information structures, which a formally generative character: based on simple starting points and limited theories or rule-sets.
But, in truth, they also seem to be at a very low level of technical sophistication regarding actual spatial optimization. Space Syntax tells you why high-streets exist and piazzas exist, and that they are good. Neat, if a bit underwhelming. What else can it do?
And, frankly, they encourage a classic problem in any technology and automation domain, which is: let's optimize what we understand, which may not be the legitimate focus of effort, rather than what needs optimizing.
I think much more of the rule-based formal generativism is required to drive design forwards, computationally or not, but those pursuing this should maybe be aware of the history and in particular the pitfalls of the Chomskyan intellectual heritage here.
The second learning we can have in thinking through how WFC-type smart-procedural modelling can learn from linguistic generatvism is applying the pragmatics turn, or at least thinking about it.
Whatever we may be able to work out in terms of rule-based generation, even with hyperstatistical support, it seems that we will inevitably arrive the same critique that pragmatics levies against Chomsky: we still don't have enough contextual information, or really stable, shared elements or rules that span different projects and supply learning.
We can't even parse existing spaces in any way that might easily lend itself to this kind of procedural design: what are the basic elements supposed to be?
If you take all the spatial hyperanalysis of say Topologic, about how roomtypes do, can and should adjoin, for example, what are we to do with orthogonal reflections such as: wouldn't it better if we lived more openplan at home, for psycho-social reasons, and less openplay at the office? You may or not believe those things (I only vaguely do), but how would you optimize for them if you aren't thinking about, and making some kind of science of them?
They are exogenous to the rule-set and its current optimization parameters, and yet might be the most definitive drivers of form for generations? And one can, and should correct them and extrapolate from there, to optimize design. The 'pragmatic turn' in design theory hasn't started yet, pace Christopher Alexander.
Anyway, hopefully surfacing this idea and intellectual history in a relatively clear form will help folks that are navigating these domains, horizons and practices. Discussion welcome in the Last Meter® community server on discord #spatialascience channel, or on twitter via #lastmeter hashtags and @jmanooch.